Chapter 14 Memory and Pointers
We have reached the final chapter for this course! In this chapter, we will seek to understand how C++ organises memory behind the scene (for instance, understanding how vectors support dynamic resizing). We will also look at concepts that are extremely important for low-level languages such as C. These include built-in arrays and pointers. However, while it is important for us as computer scientists to understand these low-level concepts, in practice we should look to use modern C++11 constructs to avoid all this low-level unpleasantness. We have already looked at one aspect of memory—the stack—previously. Here we will discuss the other important aspects of memory.
14.1 Pointers
In this section, we’ll discuss a low-level concept known as raw pointers (or simply pointers). As mentioned, avoid these in your code if possible. Instead, you should prefer to use modern C++11 smart pointers, which we will briefly mention later on.
A pointer is a variable that holds the memory address of another variable. Whereas a variable name refers to a particular value, a
pointer indirectly refers to a value by providing the address of the variable that stores the value. Accessing the underlying value through a
pointer is known as indirection. We show how this works in the diagram below, where x is a variable with value 7, and y is a pointer that
stores the memory address of x. In other words, y points to x.
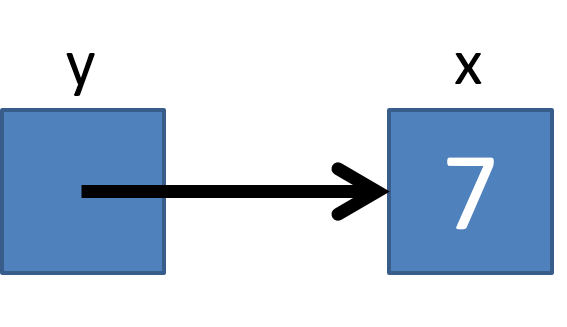
Figure 14.1: The variable y pointing to x. It is easy to see how we can use y to get the value of x by simply looking up the variable at the location it specifies.
Pointers are very closely related to the concept of references in C++. There are, however, a few differences:
Pointers can be declared without a value. References must be initialised.
Pointers can be reassigned to point at different variables. References cannot.
C++ allows for pointers to pointers, but not references to references.
Pointers can have a “null” value (i.e. pointing to “nothing” explicitly).6 References cannot.
Pointers can be used for iteration.
In general, references are safer and cleaner than pointers, and so should be preferred where possible.
14.1.1 Declaring pointers
We use the * operator in order to declare a pointer. We must also
specify the type of variable that is being pointed to. For example:
int* ptr; // space is irrelevant. Can have int * ptr; or int *ptr;The above declares a variable called ptr. This variable is of type integer pointer. That is, it is a pointer that points to an integer
variable. Note that any variable declared as a pointer must be preceded by the * character. When the * appears in a declaration, it is not
an operator. Rather, it simply indicates that the variable is a pointer.
Pointers can point to objects of any type. Recall that the const keyword can be used to create constant, unchanging variables. It can
also be used in conjunction with pointers to ensure that the pointer cannot point to anything else. The examples below show different kinds
of pointers being declared. In order to understand the exact type of the pointer, we can read the declaration from right-to-left.
| Example | Comments |
|---|---|
double* ptr; |
A pointer to a double. |
int** ptr; |
A pointer to an integer pointer. |
const int* ptr; |
Read it from right-to-left! It is a pointer to an integer which is constant. Thus the integer is constant, the pointer is not. |
int* const ptr; |
Read it from right-to-left! It is a constant pointer to an integer. Thus the pointer is constant, the integer is not. |
const int* const ptr; |
A constant pointer to a constant integer. Both the pointer and integer are constant. |
14.1.2 Initialising pointers
Pointers should be given the memory address of the variable they point
to, or they may be set to “point to nothing.” The latter are known as
null pointers. To create a null pointer, use the C++11 keyword
nullptr. Prior to C++11, either 0 or NULL was used.
int* a = nullptr; //C++11
int* b = 0; //prior to C++11
int* c = NULL; //prior to C++11Recall that the & operator can be used to get the memory address of a variable. Thus an example of initialising a pointer to point to a
variable is as follows:
int y = 20
int* xPtr = &y //points to y
int x = 10;
xPtr = &x //now points to xNote that the * operator is only used during declaration. Otherwise,
we simply refer to the pointer by its name. If x is stored at location
0xffee, then the value of the pointer will be 0xffee. Note that the
address operator must be applied to a variable. It cannot be applied to
a constant or temporary expression, since they have no valid memory
location. For instance, the following is not allowed:
int *xPtr = &(12 * 2); //the value 24 has no memory location! 14.1.3 Dereferencing pointers
In what is a slightly confusing setup, if we want to retrieve the
variable that a pointer refers to, we must use the indirection or
dereferencing operator *. This is known as dereferencing a pointer.
Note that * now plays two roles: when used in a declaration, it
specifies that the variable is a pointer. Outside of that, it extracts
the variable being pointed to. An example of this is below:
int x = 10;
int *xPtr = &x;
cout << "Address of x: " << &x << endl;
cout << "Value of xPtr: " << xPtr << endl;
cout << "Value of x: " << x << endl;
cout << "Value of *xPtr: " << *xPtr << endl;
x = 0; //change x's value
cout << "Value of *xPtr: " << *xPtr << endl;
*xPtr = 42; //change x through the pointer
cout << "Value of x: " << x << endl;
/* Output
Address of x: 0x7fffedda4f04
Value of xPtr: 0x7fffedda4f04
Value of x: 10
Value of *xPtr: 10
Value of *xPtr: 0
Value of x: 42
*/Note that the memory location of x and the value of xPtr are the
same. Thus the pointer is references x and when dereferenced, the
value of x is returned.
14.1.4 Passing pointers
Recall that we have previously covered pass-by-reference and pass-by-value. Pointers can also be passed to functions (by value), but because it points to an object, we can modify the original object in our function, just as in pass-by-reference. In the following code, we illustrate how to achieve this, with a comparison to passing by reference:
#include <iostream>
using namespace std;
//by value
int cubeByVal(int x){
int t = x * x * x;
return t;
}
//by reference
void cubeByRef(int &x){
x = x * x * x;
}
//by pointer
void cubeByPtr(int *x){
*x = (*x) * (*x) * (*x);
}
int main(){
int number = 2;
cubeByVal(number);
cout << "After pass-by-value: " << number << endl;
cubeByRef(number);
cout << "After pass-by-reference: " << number << endl;
cubeByPtr(&number);
cout << "After pass-by-pointer-value: " << number << endl;
}
/**
After pass-by-value: 2
After pass-by-reference: 8
After pass-by-pointer-value: 512
**/Note that on Line 27, we pass the address of the variable to the
function, and on Line 17, the function parameter is of type pointer.
Thus the pointer parameter is assigned the value of the memory address
of number. Note also on Line 18 that we use the dereferencing operator
to access the variable being pointed to. This allows us to get and then
set its value.
14.2 Built-in arrays
A concept closely related to pointers are built-in (or C-style) arrays. These arrays are fixed-size data structures, and much like C++11 arrays, we must specify their type and constant size upfront.
Warning: in C++, arrays must have constant length. However, a number of compilers have extended the C++ language to allow for variable-length arrays. This is not valid C++ code, so do not use it. In particular, it might work perfectly fine on your computer, but fail on the marker.
The declaration of a built-in array differs from C++11 arrays, as shown below:
array<int, 1000> arr1; //C++11 array
int arr2[1000]; //built-in arrayMost of what we have discussed about C++11 arrays applied to built-in arrays, such as initialisation:
int d[5] = {1, 2, -1, 3, 3};and the ability to index elements with the [] operator. However,
built-in arrays do not possess functions such as size(). This means
built-in arrays do not even know their own size (more on this in a bit).
Even worse, when built-in arrays are passed to a function, they turn
into pointers (this is called decaying)! This means that the array is
implicitly converted to a pointer that refers to the memory address of
its first element. In other words, a built-in array arr is equivalent
to &(arr[0]).
To illustrate, consider the two functions below. Their purpose is to loop through a built-in array and print out all its elements. The first function accepts an array as input along with its size, while the second accepts a pointer as input along with the array’s size.
void printArray1(const int arr[], int size){
for (int i = 0; i < size; ++i){
cout << arr[i] << endl;
}
}
void printArray2(const int *arr, int size){
for (int i = 0; i < size; ++i){
cout << arr[i] << endl;
}
} Both of these functions are perfectly valid and will work, But importantly, from the compiler’s perspective, they are both identical. In other words, the compiler does not differentiate between a function that receives a built-in array and one that receives a pointer. To the C++ compiler, they are both pointers.
This is problematic, because as programmers, we now need to keep track and remember whether a pointer is a just a regular pointer, or is in fact an array (since they both look the same)! This is a common source of errors and is a reason for why C++11 arrays were introduced.
An additional issue with built-in arrays is that they cannot be compared using equality or relational operators. For example, if we wanted to know if two arrays contain the same values, we could use the double equal sign with C++11 arrays. Built-in arrays, however, are essentially pointers. Thus an equality check would simply test whether both arrays point to the same memory location.
Finally, built-in arrays do not in general know their own size, and so a function that accepts a built-in array must also take its size as an argument, which is time-consuming and annoying. They can also not be assigned to one another, since the C++ language forbids this.7
On the plus side, built-in arrays can still be made to work with the
functions provided by C++ such as sorting and searching. To do so, we
must include the <iterator> header file. Then sorting, for example,
looks like this:
sort(begin(arr), end(arr));Ultimately though, there is no real good reason to use built-in arrays. Simply use C++11 arrays and vectors instead!
14.2.1 Getting the size of a built-in array
We can in fact compute the number of elements of a built-in array using
the sizeof operator. However, we can only do this provided that the
array has not yet decayed to a pointer. As soon as that happens, the
array size cannot be recovered.
The operator sizeof determines the size (in bytes) of an array or any
other data type, variable, or constant at compile time. When applied
to a built-in array, it returns the total number of bytes in the array.
However, when applied to a pointer, it returns the size of the pointer,
not what the pointer references. In the example below, we see that we
can compute the number of bytes in the full array, but as soon as the
array is passed to the function, it decays to a pointer and the array
size is lost.
#include <iostream>
using namespace std;
int getSize(double arr[]){
return sizeof(arr);
}
int main(){
double numbers[20];
cout << "The number of bytes in the array is "
<< sizeof(numbers) << endl;
cout << "The number of bytes according to getSize() is "
<< getSize(numbers) << endl;
return 0;
}
/*
Output:
The number of bytes in the array is 160
The number of bytes according to getSize() is 8
*/This occurs because the compiler treats the getSize function as
size_t getSize(double* arr){
return sizeof(arr);
}and the size of a pointer is 8 bytes.
If we want to determine the number of elements in a built-in array, we must ensure that it has not decayed to a pointer. Then we can use the following expression, which will be evaluated during compilation.
sizeof(arr)/sizeof(arr[0])The following code illustrates the effect of the sizeof operator on
different data types on a 64-bit computer. If you have a 32-bit machine,
you may get different results. Note that we only need to use round
brackets with sizeof when we want to compute the size of a type (e.g
sizeof(char).
#include <iostream>
using namespace std;
int main(){
char c; // variable of type char
short s; // variable of type short
int i; // variable of type int
long l; // variable of type long
long long ll; // variable of type long long
float f; // variable of type float
double d; // variable of type double
long double ld; // variable of type long double
int array[20]; // built-in array of int
int *ptr = array; // variable of type int *
cout<< "sizeof c = " << sizeof c << " "
<< "sizeof(char) = " << sizeof(char) << endl
<< "sizeof s = " << sizeof s << " "
<< "sizeof(short) = " << sizeof(short) << endl
<< "sizeof i = " << sizeof i << " "
<< "sizeof(int) = " << sizeof(int) << endl
<< "sizeof l = " << sizeof l << " "
<< "sizeof(long) = " << sizeof(long) << endl
<< "sizeof ll = " << sizeof ll << " "
<< "sizeof(long long) = " << sizeof(long long) << endl
<< "sizeof f = " << sizeof f << " "
<< "sizeof(float) = " << sizeof(float) << endl
<< "sizeof d = " << sizeof d << " "
<< "sizeof(double) = " << sizeof(double) << endl
<< "sizeof ld = " << sizeof ld << " "
<< "sizeof(long double) = " << sizeof(long double) << endl
<< "sizeof array = " << sizeof array << endl
<< "sizeof ptr = " << sizeof ptr << endl;
return 0;
}
/*
Output:
sizeof c = 1 sizeof(char) = 1
sizeof s = 2 sizeof(short) = 2
sizeof i = 4 sizeof(int) = 4
sizeof l = 8 sizeof(long) = 8
sizeof ll = 8 sizeof(long long) = 8
sizeof f = 4 sizeof(float) = 4
sizeof d = 8 sizeof(double) = 8
sizeof ld = 16 sizeof(long double) = 16
sizeof array = 80
sizeof ptr = 8
*/
14.2.2 Pointer arithmetic
Because pointers hold memory addresses (which are just hexadecimal
numbers), we can do a special kind of arithmetic with them. In
particular, we can increment and decrement a pointer, add or subtract an
integer, and subtract one pointer from another. To illustrate this,
assume that an integer takes up 4 bytes, and that we have a built-in
integer array int arr[5] that starts at address 3000. (We will use
decimal numbers below just for readability.) Then we can visualise the
memory layout as follows:
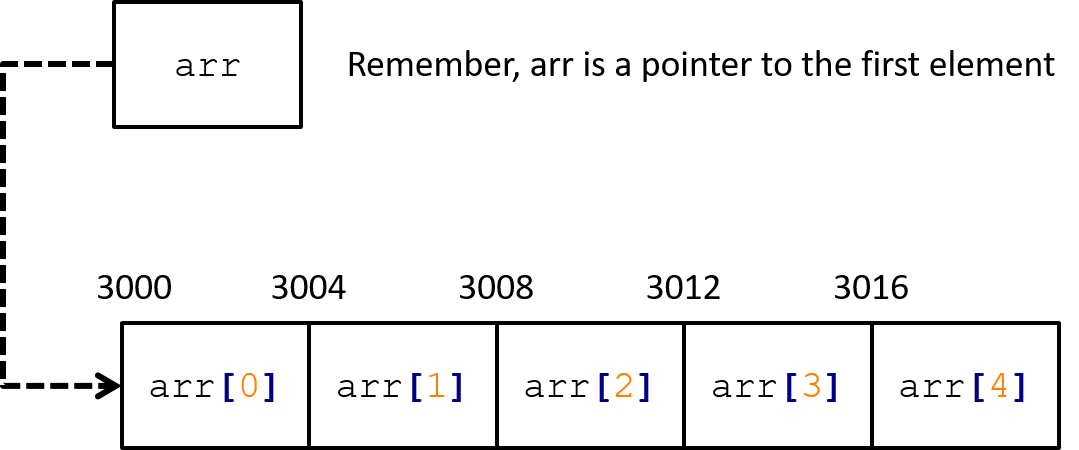
Figure 14.2: The built-in array. Note that the first element is at location 3000, the second at 3004 and so on. This is because each integer is 4 bytes wide.
Given that the value of arr is 3000, in normal arithmetic we would
have \(\texttt{arr} + 2 = 3002\). Pointer arithmetic is slightly different
though. As arr is an array of integers, we actually add the size of
an integer times 2. So we get \(\texttt{arr} + (2 \times 4) = 3008\).
Note that 3008 is the memory location at index 2, and so we have
*(arr + 2) = arr[2]. We can thus use pointer arithmetic to access
elements at certain locations.
If we have two pointers that point to the same built-in array, we can
subtract one from another. For instance, if ptr1 contains the address
3000 and ptr2 contains the address 3008, then ptr2 - ptr1 represents
the number of built-in array elements from ptr1 to ptr2, which in
this case is \((3008 - 3000) / 4 = 2\). Thus pointer subtraction is
equivalent to the “distance” between two pointers.
14.3 Dynamic memory allocation
In this section, we will look at the part of memory known as the heap. Before that, recall our discussion of the stack, which is where local variables are stored. Recall that the compiler automatically manages the stack for us. TO achieve this, it must know how much memory to allocate beforehand (this is why array sizes must be known upfront). Furthermore, the stack size is quite small. This reduces overhead and makes everything very quick, but it means we may run out of memory if we try allocate a large array (e.g. an array with 100 million elements).
There is another problem with the stack, which can be seen in the example below. In this program, we create a function that will create and return a built-in array of size \(N\), where each element has value \(x\). Can you spot the problem?
int* create(const int N, int x){
int arr[N];
for (int i = 0; i < N; ++i){
arr[i] = x;
}
return arr;
}
int main(){
int *arr = create(3, 3);
}The problem here is that arr is a local variable that is stored in its
function’s stack frame on the stack. As soon as the function returns,
its scope ends, but the address of the array is returned anyway. We now
have a pointer to some invalid memory that may have been destroyed or
reused!
14.3.1 The heap
The heap solves the problems associated with the stack. Unlike the stack, the heap supports dynamic allocation. This means that we, the programmer, decide when objects are to be destroyed or deallocated, and we must do so ourselves. The heap is also much larger, although as a result a bit slower. Finally, unlike the stack where memory must be allocated upfront, the heap allows for allocation to occur at any time. This is how a vector is able to resize itself whenever it needs to.
In order to allocate memory on the heap, we must use the new keyword.
When we do so, memory is allocated on the heap and a pointer is returned
to us. When we want to free up or deallocate that memory, we must apply
the delete keyword to the pointer. For built-in arrays, we use the
new[] and delete[] keywords respectively. If we forget the square
brackets, then only the first element of the array will be deallocated.
You may encounter functions such as malloc, calloc and free when
looking at alternating resources. These are for C, not C++, and should
never be used!
14.3.1.1 Allocation examples

Figure 14.3: In the above example, we allocate a double variable on the heap. The variable is stored in the heap, and we receive a pointer to this variable. The pointer is stored on the stack. The variable on the heap will remain there forever until we decide to delete it.

Figure 14.4: This example is identical to the previous one, except here we also specify the value of the variable on the heap.
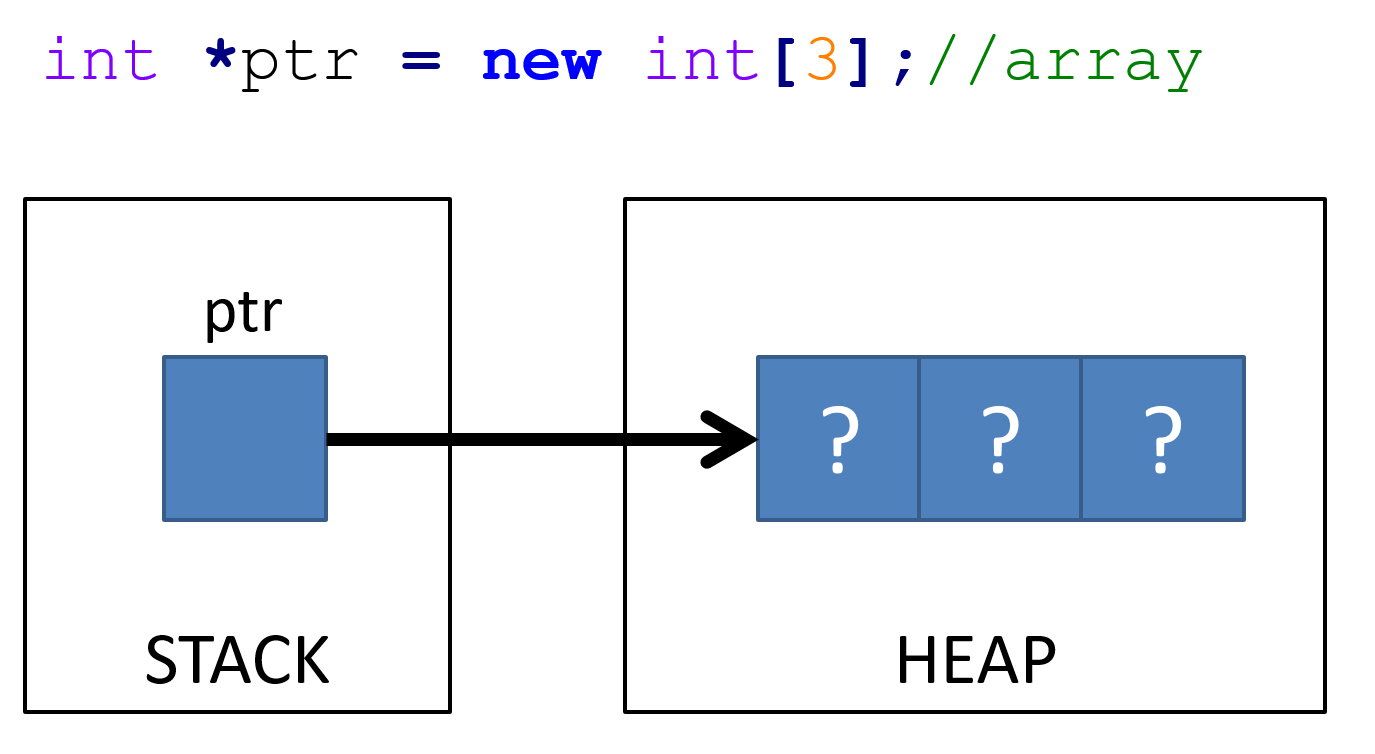
Figure 14.5: Here we allocate a built-in array on the heap. 3 elements are allocated on the heap, and a pointer to the first element is returned.
In all these cases, it is important to note that variables allocated on the heap will remain there until we explicitly delete them. However, the pointer is allocated on the stack and so is automatically destroyed by the compiler. Thus if we lose the pointer, we can no longer access the memory on the heap, and if we have yet to delete the memory, then it will never be deleted! This is known as a memory leak.
14.3.1.2 Deallocation examples
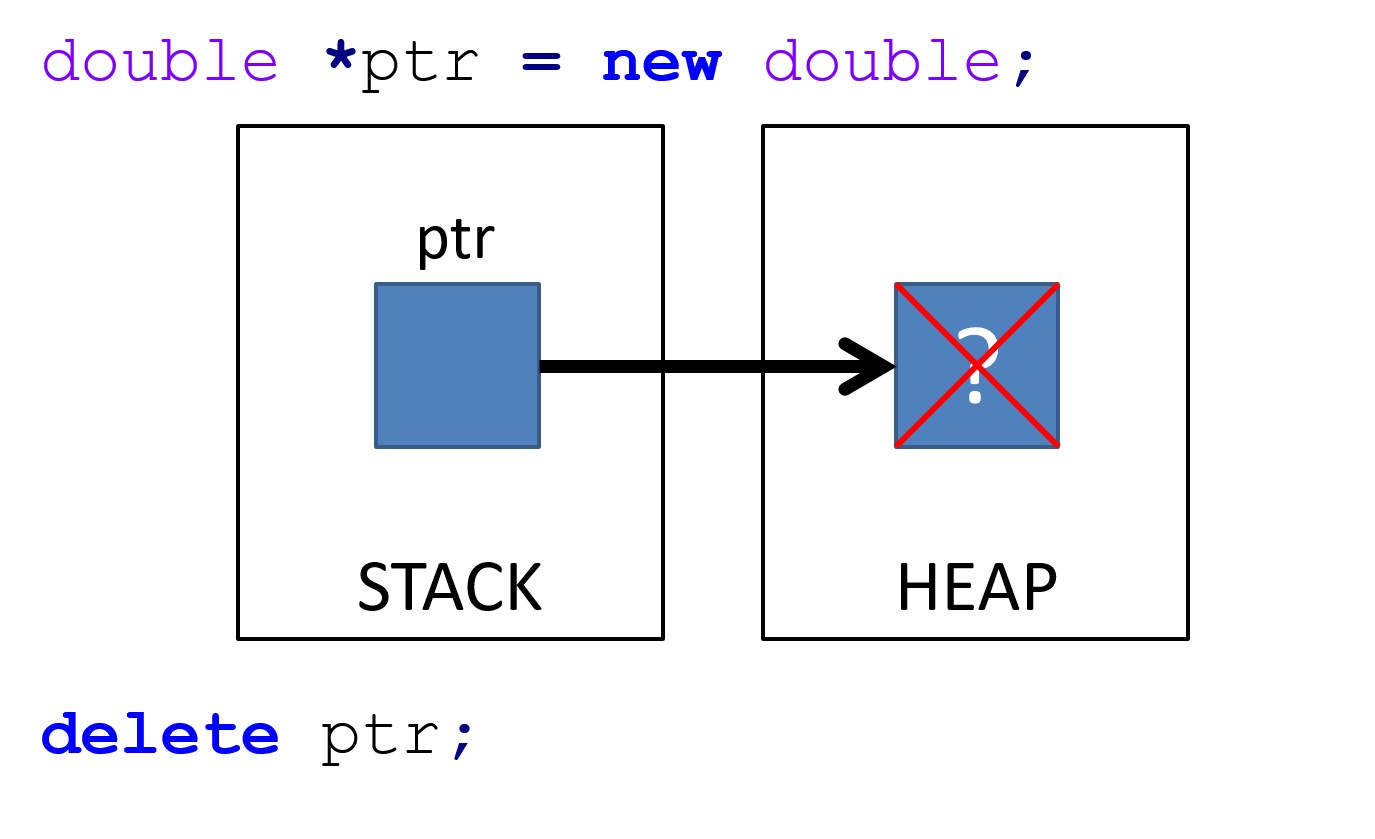
Figure 14.6: In the above example, we allocate a double variable on the heap. We then use the pointer that references it to delete it, thus freeing up memory.
![Here we have allocated a built-in array on the heap. We apply the `delete[]` operator the pointer that references it to delete it, thus freeing up memory.](images/dealloc2.png)
Figure 14.7: Here we have allocated a built-in array on the heap. We apply the delete[] operator the pointer that references it to delete it, thus freeing up memory.
We can now go back an rectify the problem of creating a built-in array
inside a function. We achieve this by allocating the array on the heap,
so that it is not automatically deleted when the function returns. Note
that the size of the array N does not need to be constant, since we
are declaring the array on the heap.
int* create(int N, int x){
int* arr = new int[N];
//array on heap will survive end of scope
for (int i = 0; i < N; ++i){
arr[i] = x;
}
return arr;
}
int main(){
int *arr = create(3, 3);
//We now have a valid pointer to data on the heap
//don't forget to delete[] at some point
}14.3.1.3 Issues with dynamic allocation
While the use of the heap solves some stack-related problems, they come with their own set of issues. Firstly, we must now remember to delete our data, or risk a memory leak occurring. Additionally, it is unclear who is responsible for deallocating the memory. For example, if we write a function that accepts a pointer to memory on the heap, should we delete the pointer inside the function or after it? A related issue is a double free error, which occurs when we try delete memory twice, and results in undefined behaviour. Finally, at any point in our program, it is hard to determine whether a given pointer is valid or has already been deleted. A pointer that references memory that has been deleted is known as a dangling pointer.
Dynamic arrays can be used to create multidimensional arrays, but creating and deleting them is not straightforward. For instance, a 2D array can be created and deallocated as follows:
int numRows, numCols;
cin >> numRows >> numCols;
int** matrix = new int*[numRows];
for (int i =0; i < numRows; ++i){
matrix[i] = new int[numCols];
}
//deleting is not straightforward
for (int i =0; i < numRows; ++i){
delete[] matrix[i];
}
delete[] matrix;But look how much easier it is to simply use a vector!
int numRows, numCols;
cin >> numRows >> numCols;
vector<vector<int>> matrix(numRows, vector<int>(numCols));
//no need to clean upAll in all, our main takeaway is that built-in arrays (whether declared on the stack or heap) cause many issues that are ultimately unnecessary. C++11 arrays are simply better built-in arrays, while vectors are better dynamic built-in arrays, and so we should just use those instead.
14.4 Smart Pointers
Our final section is that of smart pointers, which were introduced in
C++11. To use smart pointers, we must include the <memory> header
file. Smart pointers act exactly like the pointers we’ve seen so far,
but they do not require us to delete them. When a smart pointer is
deallocated by the compiler, the memory it references (whether on the
stack or heap) is automatically freed. Thus smart pointers prevent
memory leaks from occurring. There are two types of smart pointers in
C++11: unique and shared.
A unique pointer ensures that only one pointer may point to a variable in memory. This prevents multiple pointers referencing the same object. For example, we can create a unique pointer thusly:
{
unique_ptr<int> ptr (new int(3));
// Going out of scope...
}
// I did not leak my integer here!
// The destruction of unique_ptr called deleteHowever, if we try to assign multiple pointers to the same object, our program will crash:
unique_ptr<int> ptr (new int(3));
unique_ptr<int> ptr2 = ptr; //invalid!A shared pointer is similar to a unique pointer, but does allow for multiple pointers to reference the same object. An example of creating a shared pointer:
{
shared_ptr<int> ptr (new int(3));
// Going out of scope...
}
// I did not leak my integer here!
// The destruction of shared_ptr called deleteWe can assign multiple shared pointers to the same object with no issue:
shared_ptr<int> ptr (new int(3));
shared_ptr<int> ptr2 = ptr; //no problem!The following functions are useful for creating shared and unique pointers:
auto x = make_shared<string>("abc");
auto y = make_unique<int>(12);However, the C++ committee forgot to include make_unique in C++11
(make_shared is present)! make_unique was finally introduced in C++14.
14.5 Summary
To summarise, the heap can be used to store large amounts of data (and indeed this is where vectors store their data). While you need to understand these underlying concepts, try not to explicitly use them in your code—use smart pointers instead of raw pointers, and vectors instead of dynamic arrays wherever possible!
This is a very good reason for using pointers. For example, imagine you wrote a function that searches an array and returns a pointer to the element in the array with a particular value. What if there is no such element matching that value? What should we return in that case? A pointer that points to “null” is a good candidate in this case.↩︎
The reason it is forbidden is that C++ was initially designed to be backward compatible with its predecessor programming languages B and C. Since these languages do not allow for one array to be assigned to another, neither does C++.↩︎