Chapter 7 Introduction to C++
7.1 Outline
The next few chapters cover the content we have already discussed in the first half of the course. We’ll assume that you are familiar with basic programming ideas in Python, and so we will briefly recap these, illustrating how C++ and Python differ in these regards. The main takeaway here is that the underlying concepts remain the same—regardless of the language, ideas like loops and variables are constant. The only difference is in the syntax—that is, the way we actually write down an if-statement or for-loop, which differs from language to language.
Once we have covered the basics, we will move on to new conceptual content. This primarily involves the idea of memory allocation. In Python, for example, memory allocation is automatically handled by the interpreter, and so is not the concern of the programmer. However, C++ allows the programmer to manually specify and control this—this is useful for programming in embedded systems such as ATMs, washing machines and airplanes. As such, we will look at how variables are allocated (and de-allocated) in memory.
However, it is important to note that these low-level concepts are often unnecessary. There are many modern techniques and advances to the C++ language that means it is possible to write code without needing to ever manage memory manually. However, as well-rounded computer scientists, it is our job to understand how things work behind the scenes, even if we will never explicitly write a real-life program in such a way.
As a final note, throughout these notes we will include either full and complete C++ programs as examples, or (where appropriate) snippets of programs. An example of a snippet is given below. These snippets are valid lines of C++ code, but they are not full, self-contained programs. In other words, attempting to execute the code will fail, since it is simply part of a large, complete C++ program. We will look at a full C++ program that can be executed in the next sections.
cout << "Hello world" << endl;7.2 Introduction
In this chapter, we will take a first look at the C++ programming language and how it differs from Python. Before we do so, a reminder that programming languages are nothing but tools—there is no one “best” language, and each are designed with some use case in mind. For instance, the Java programming language is designed to be very structured and solid, and so is a good choice for enterprises or organisations with very large teams all working on the same product. C++, on the other hand, generally provides greater performance when compared to Python and Java, and so would be a good choice for, say, physics simulators and video game engines, which require speedy computation.
The main difference between C++ and Python can be seen in the times when they were created. The first version of Python was released by Guido Van Rossum in 1991, while C++ was invented by Bjarne Stroustrup in 1979. Thus C++ was designed to run on older hardware, which was slower and had less memory. In particular, computers of that time had on the order of 10KB of memory, which meant that memory had to be used and allocated very precisely. Nowadays, memory is less of an issue with most machines have 8GB or more, and so modern languages like Python do not burden the programmer with manual memory allocation.
In general, the main differences between Python and C++ can be summarised in that C++ is:
- more low-level. It exposes more of the inner workings of the program (such as direct memory allocation and addressing) to the user.
- more dangerous. Since C++ gives the user more control and responsibility, the programmer is ultimately responsible for managing more aspects of the program and writing more code. Since we are imperfect, this means that there’s a greater chance of making more mistakes.
- more complex. C++ is a difficult language, because it strives above all else to be useful to everyone. Thus it has features that allow it to perform extremely low-level tasks (such as determining CPU cache line sizes), as well as be competitive with high-level modern languages like Python. It has also resolved that it will always be compatible with previous versions of itself. Thus if a bad idea was introduced in 1985, the 2020 version of C++ is required to support it, no matter what.1
However, we should not be discouraged by the sheer complexity of C++, since we will not be looking to write overly-complex or convoluted code. In fact, the parts of C++ we will be using are in general very clean, simple, and straightforward to understand. In comparing C++ to Python, we will see that the concepts of sequencing, branching, looping, functions and input/output are extremely similar, and so will hopefully be readily understandable.
The major differences between the two languages are in their syntaxes (how we actually write down a for-loop or if-statement), their typing (Python is a dynamically typed language, whereas C++ is statically typed), and their execution (Python is interpreted, whereas C++ is compiled). We will investigate each of these differences in detail in the next few sections and subsequent chapters.
7.3 The Compiler
Recall that Python is an interpreted language. This means that our code is executed by an interpreter, which is a special program written for each architecture (such as Windows, Ubuntu, etc). The interpreter takes each line of Python code, converts it to the appropriate machine code, and then executes it on the underlying computer. This process is repeated for every line until the program is finished. Importantly, this conversion happens every single time we run the code.
By contrast, C++ is a compiled language.
A compiled language uses a , which is a special program written for each architecture that accepts the C++ code and produces low-level (machine) code.
This is quite similar to how the interpreter converts Python code to machine code, but importantly here the compiler does not execute the code.
A separate process is used to execute the resulting low-level code which was output by the compiler.
This is the most important difference because it means that the conversion from our high-level code to machine code only happens once.
After that, the machine code is directly executed every time we run the code.
Compare this to interpreted languages, where the conversion happens every single time the code is executed.
As you can imagine, this conversion process adds additional overhead.
As a result, compiled languages are often significantly faster than interpreted ones.
The figure below gives a rough illustration of the difference between compiled and interpreted languages.
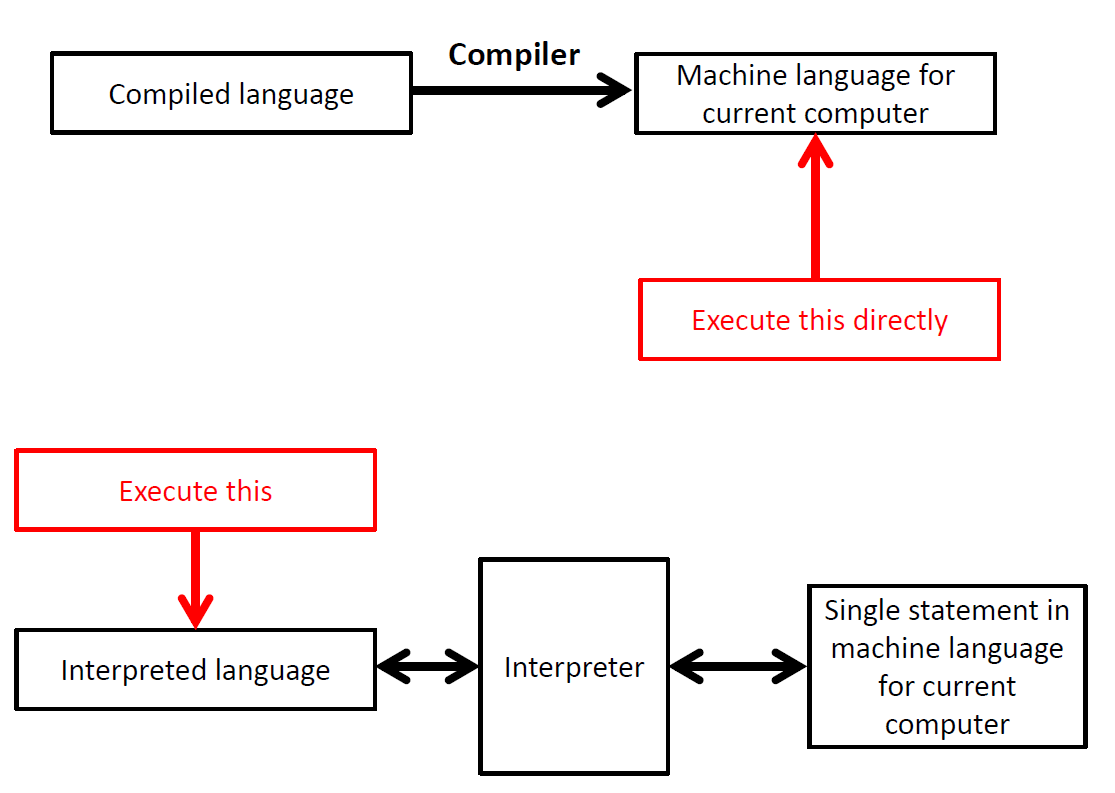
Figure 7.1: The difference between compiled and interpreted languages. In a compiled language, it is the output of the compiler (the machine language) that is directly executed on the underlying computer every time the program is run. By contrast, the interpreted language must pass through the interpreter to be converted to machine code every time it is executed. One downside of the compiled approach is that if the code changes in any way, it must be recompiled before being executed.
7.4 Compiling our First Program
Before we look into the details of how compilation works, let’s see it in practice.
We’ll start by creating a simple C++ program that will display the text Hello, world! to screen.
Recall that to achieve this in Python, we would simply write
print("Hello, world!)By contrast, the corresponding C++ program looks like this:
#include <iostream>
using namespace std;
int main(){
cout << "Hello, world!" << endl;
return 0;
}At this stage, do not worry about the exact details of the program, since we will shortly analyse it in detail. Simply note that it requires many more lines of code to achieve the same result as the Python program—with greater speed and control, comes greater responsibility!
7.4.1 Compilation in Ubuntu
In this section, we will demonstrate how to compile and execute a C++ program in Ubuntu (and which should work roughly the same on macOS). If you are using a Windows PC, please watch the video at the end of this section. Importantly, regardless of the operating system, the work going on behind the scenes remains the same. So even if you have Windows, please read this section carefully.
First off, create a new text file called helloWorld.cpp and type the above code into it.
Be sure to save the file.
Next, open the terminal in the same directory and enter the following command to compile the program:
g++ -Wall -std=c++11 helloWorld.cpp -o helloWorldThe above command turns the text file into a program, and outputs an executable file called helloWorld.
If you receive any error messages in terminal, you will need to correct the errors in your code, save the file, and rerun the command.
Note that if everything has gone well, the terminal will not display anything.
You should now have a new file in the directory called helloWorld.
This is the file produced by the compiler that can be directly executed on our computer.
To run it, enter the following into the terminal:
./helloWorldThe following output should now be displayed in the terminal window: Hello, world! Note that every time you make a change to the code, you will need to save your file and run the above g++ command before executing it.
Before we move on, let us quickly have a look at the command we typed in order to convert our C++ code into something that can be executed. For reference, our command we used was
g++ -Wall -std=c++11 helloWorld.cpp -o helloWorldg++is the built-in compiler on Ubuntu. This is mandatory.-Wallforces the compiler to print all warnings to the terminal. Warnings are not errors, and so need not be fixed, but they are often a good indication that something may be wrong. Note that this is optional and does not need to be present to compile.-std=c++11tells the compiler that we are using the 2011 version of C++. In this course, this will be the standard version, but not that the latest version is 2020. If you do not specify it, your compiler will use its default version (which varies depending on your setup). If your compiler by default uses an older version, then some of the code in these notes will not execute! Thus be sure to specify the 2011 version to avoid these issues. Note that this is optional and does not need to be present to compile. However, the marker uses this version, and so if you leave it out, there is a risk that your program will execute perfectly fine, and then be marked incorrect by the marker. For this reason, we encourage you to always specify the 2011 version.helloWorld.cppis the name of the text file you have written your code in. You must specify this to let the compiler know which file you would like compiled. This is mandatory.-o helloWorldis a flag that specifies what the name of the file created by the compiler should be called. In this case, the file will be calledhelloWorld, but you could pick any name you wanted. Note that this is optional. If you do not specify an output file name (that is, if you leave off-o myFileName) then by default the compiler will produce an output file with the namea.out.
The video below shows us compiling a C++ file on Ubuntu.
The video below shows us compiling a C++ file on Windows.
7.5 The Compilation Cycle
Before we look at the details of the above program, we first need to understand what just happened. How did the compiler take our code and convert it into something that can be directly executed on our machine? In C++, this is achieved through the compilation cycle, which consists of the following steps:
- edit,
- pre-processing
- compile,
- link,
- load, and
- execute.
The first four phases are responsible for actually creating the executable file, and the remaining two are responsible for executing it.
7.5.1 Editing
In this phase, the programmer (ourselves) simply writes the C++ code and saves it in a text file. This text file is known as the source file.
7.5.2 Pre-processing
This phase handles any directives, which are specified by a line beginning with the # symbol.
The most common use case here will be any code that we import.
In Python, you may have written import math in order to gain access to Python’s mathematical functionality.
C++ has a similar system, but instead of writing import, we write #include.
To import mathematical functions for example, we would write
#include <cmath>When we do this, the pre-processor will search for a file called cmath.h and replace that line with the file’s entire contents.
Note that the included file may contain other #include statements, which themselves may contain other #include statements, and so on.
The contents of all these files are all included (up to some limit).
7.5.3 Compiling
In this phase, the pre-processed file containing the written code and any included code is converted into machine code that can run on the underlying computer. The files output by the compiler are called object files. If there are any errors in the code, the compiler will fail to create the object files and will instead print the errors to the screen. You will then need to use this information to locate the errors and fix them, before recompiling your program.
These errors are known as compile-time errors, since they are discovered during the compilation step. These differ from run-time errors, which only occur when the program is running. For example, imagine we have written perfectly good code that computes the average class mark. Everything is correct, and so the compiler detects no errors. Now imagine a user comes and decides not to enter any marks, but wishes to compute the average. Our code will then likely have a division by \(0\) error, because we had not budgeted for such an event. However, the compiler cannot detect the error because it only happens once the program is running and the user does something strange and unforeseen.
7.5.4 Linking
In this step, if the compiler has output multiple object files, then they are all combined into one final executable file.
In this course, we will only ever write code in a single file.
However, a C++ program may have multiple source files.
Each of them is converted to an object file during the previous phase, and the linker is responsible for combining them all into one big file.
Additionally, any libraries that were required (libraries are object files that other people* have created) are combined here.
An example of a library file might be an object file that allows for drawing and on-screen animations.
Note that these library files are object files, which differs from those we have #included in the pre-processing phase (which were source files).
7.5.5 Loading
At this point, the linker has output an executable that can be run on the current machine. In the loading phase, the executable is loaded from disk and placed into RAM ready to be executed. At this stage, memory is set aside for the program that only it will be able to access.
7.5.6 Executing
At this stage, the program is actually run. This simply involves transferring the machine code, which was loaded into memory, to the central processing unit (CPU) for execution. The CPU will then execute the program one line at a time, following each instruction, until the program terminates.
An illustration of the full cycle is given below:
.](images/cycle.png)
Figure 7.2: The compilation cycle given multiple source files. In this course, we will generally only ever have one source file. Diagram courtesy of MIT OpenCourseWare.
7.6 Analysing our First Program
To conclude this chapter, let us take a moment to analyse the Hello, world! program we looked at earlier.
For convenience, we repeat the program below, adding comments for greater clarity
/*These are comments. They are used to assist the programmer.
They do not affect the program in any way.
Write whatever you want*/
#include <iostream> //preprocessor directive (use input/output)
using namespace std; //use standard definitions
//This is the "main" function. C++ will start executing code here
int main(){ //bracket signals the start of the main function
cout << "Hello, world!" << endl; //display with a new line
//main must return an integer. 0 means success, else fail
return 0;
} //end of the main function7.6.2 The Include Directive
Line 4 is a preprocessor directive.
Before compilation actually occurs, the directive instructs the compiler to replace the line with the entire contents of the specified file.
In this case, the contents of the standard library file iostream (which defines the standard C++ input and output functions) is added to the file. Note that the included file may contain other #include statements, which themselves may contain other #include statements, and so on.
The contents of all these files are all included (up to some limit).
Note that in Python, there was no need to import any input or output functionality, since it is always present by default.
In contrast, C++ does not make this assumption and so it is up to us, the programmer, to #include it.
7.6.3 Namespace
This is a slightly advanced topic, and so we will only cover it briefly here. Do not worry too much if you do not fully grasp the concept, just know that Line 6 is necessary to make everything work.
In C++, identifiers such as variables and functions can be defined within a context called a namespace.
This is mainly to prevent clashes between variables and functions defined by ourselves and others.
For example, if I were to write a square-root function, I would like to be able to call it sqrt without having to worry that C++ has its own function with the exact same name.
To overcome this, C++ uses namespaces to keep everything separate.
All the functionality provided by C++ by default is inside the std namespace.
In our example above, I am free to call my function sqrt, because C++ has placed its sqrt function inside the standard namespace, and so its actual name is std::sqrt.
It is possible to define your own namespace to ensure that your variables and definitions do not conflict with either the standard ones, or someone else’s, but we won’t need to do that in this course.
One downside is that it can get quite tiring writing std:: everywhere.
Thus on Line 6, we tell the compiler we’ll be using the standard namespace by default.
Both cout and endl reside in the standard namespace, but because we said we’ll be using the standard namespace, we do not need to specify their namespace.
If we omit Line 6, we’d have to change Line 10 to read:
std::cout << "Hello, world!" << std::endl;For our purposes, it is simply easier to use the standard namespace and not have to worry about typing the std:: qualifier every time.
7.6.4 The Main Function
Every C++ program must have a special function called main, which defines the entry point of the program.
That is, it defines where the code should start being executed from.
All C++ programs begin processing at the first executable statement in main.
We will look later at how C++ defines and structures functions, but for now it suffices to note that the int in front of main declares main to be a function that is expected to return an integer.
Contrast this to Python, where we did not need to specify what type of data was being returned by a function.
The function body is defined by the opening and closing curly braces. Again contrast this to Python whose function bodies were defined by indentation. It is considered good practice to indent the text in the function body by a certain amount of space, but unlike Python this is not necessary.
Line 10 is equivalent to Python’s print function, and will display the specified string to the terminal screen.
The endl term is a built-in function that will insert a newline when printing (essentially equivalent to \n).
There is a lot to say about input and output in C++, but we will defer that discussion to later chapters.
Finally, Line 12 specifies that the function returns the integer \(0\). The operating system expects all programs to return an integer indicating whether they have successfully completed, or whether they terminated with some error. \(0\) indicates that the program completed successfully, while any other integer indicates some error occurred. For example, if your program had prompted for user input and the user typed in something that the program was not prepared to process, one could signify this to the operating system by returning a 1. When this line is encountered, processing in the CPU returns to the operating system.
Finally, note that all statements in C++ are terminated by a semi-colon. Preprocessor directives and function definitions are not statements, and therefore do not end with a semi-colon.
7.7 Summary Lecture
This is a very good reason for using pointers. For example, imagine you wrote a function that searches an array and returns a pointer to the element in the array with a particular value. What if there is no such element matching that value? What should we return in that case? A pointer that points to “null” is a good candidate in this case.↩︎
7.6.1 Comments
We have added comments to the program. As in Python comments are annotations that can be made to the code to explain exactly what’s going on, or to help with readability. They are ignored by the compiler, and so do not affect the functionality of the program in any way. There is no need to comment every single line—use them only when they help in understanding the code. There are two types of comments: C++ -style comments, which begin with
//and span a single line, and C-style comments, which wrap the comment in/*and*/and can span multiple lines. Both are perfectly valid in C++.