Chapter 11 Functions
In this chapter, we will discuss C++ functions, which once again closely parallel Python’s versions. One main difference is in the way the functions are declared—because C++ is a statically typed language, we will need to specify data types in its declaration. After that, we will then discuss how variables are passed into functions, as well as how long a variable exists in memory for.
11.1 Functions
Functions are groups of statements that, taken together, perform a task.
Breaking a program up into these modular blocks makes it easier to
understand, maintain and test for errors. All C++ programs have at least
one function (main()), and even the most trivial programs can define
additional functions. The way code is divided into functions depends on
the programmer and task at hand, but the most logical course of action
is to ensure that each function performs only a single task.
We start by first showing the general form of a Python function:
def <function_name>(<params>):
# function bodyC++ differs in that we must specify the parameter types, as well as the
type of object returned by the function. If the function does not
return anything, then its return type is void. The general form of the
C++ function is thus:
<return_type> <function_name>(<params>){
// function body
}Once again, notice that we use curly braces instead of indentation and colons to define the body of the function. Here are some snippets of functions that have different numbers of parameters and different return types:
// the main function returns an int, and has no params
int main(){
cout << "Hello, world!" << endl;
return 0;
}
// the function has no params, and no return
void greet(){
cout << "Hello" << endl;
}
// the function takes as input two doubles, and returns a double
double add(double x, double y){
return x + y;
}
// the function accepts a string and int, and returns nothing
void greet(string name, int numTimes){
for (int i = 0; i < numTimes; ++i){
cout << "Hello " << name << endl;
}
}Some important properties of functions are as follows.
Like variables, C++ functions must be declared before they are first used.
Unlike Python, C++ functions may return at most one object via its return statement. The object being returned must match the return type that has been specified. So if the function is supposed to return a string, it cannot return an integer, for example. Similarly, if the function has a return type of
void, then it cannot return anything at all.The parameters of the function are declared with their types.
Once the function returns, the variables in the parameter list, and any other variables declared inside the function, are lost.
Functions can call other functions
If a function has no parameters, then its round brackets are left empty.
11.1.1 Declaration
As with normal C++ variables, we can choose to declare a function without defining what it does. This lets the compiler know that such a function exists, and allows the programmer to define what it actually does later on. Declaring a function informs the compiler about the function’s name, the data type it returns (if any), and the parameters it accepts (if any). A function must be declared before it is used in another part of the program. The general form of a function definition in C++ is as follows:
<return_type> <function_name>(<parameter_list>);Note here that we have not specified the function body. The above is known as a function prototype (or header) and consists of the following:
11.1.1.1 Return type
A function may return a value. The return type specifies the data type
of the value the function returns. However, if the function does not
return a value, the return type is the keyword void.
11.1.1.2 Function name
This is the actual name of the function. The choice of name is completely up to the programmer, but should explain what the function actually does. The naming rules for functions follow that of variables.
11.1.1.3 Parameter list
This represents the values passed to the function when it is used (invoked). These parameters are also known as formal arguments, and list the type, order and number of parameters of a function. The parameter list, together with the function name, constitute the function signature. If you declare multiple functions, they must all have their own unique signature.2 They must differ either by parameter list or function name (or both).
11.1.2 Definition
Declaring a function lists its name, inputs and outputs, but doesn’t actually define what it does. A function definition in C++ specifies the function header, as well as its actual functionality. We may choose to first declare a function, and then define it, or we may simply define it immediately. If we define a function without declaring it, it must again happen before the function is actually used. Function definitions take the following form:
<return_type> <function_name>(<parameter_list>){
<function_body>
}where the only additional concept is the function body, which contains the collections of statements that describe what the function actually does.
The two examples below illustrate a function that is first declared and the later defined, and then the case where the function is simply defined.
#include <iostream>
using namespace std;
/*
We tell the compiler the function header,
but we don't actually provide implementation
*/
int add(int, int);
int main(){
int x = 1;
int y = 2;
cout << add(x,y) << endl;
return 0;
}
/*
The definition of add() The header here must
match the declaration
*/
int add(int a, int b){
return a + b;
}#include <iostream>
using namespace std;
/*
We define the function header and its implementation
all at once
*/
int add(int a, int b){
return a + b;
}
int main(){
int x = 1;
int y = 2;
cout << add(x,y) << endl;
return 0;
}11.1.3 Function returns
Like Python, C++ functions can return in three ways. For void
functions, a function can return by either reaching its closing brace,
or a return; statement. Non-void functions return by encountering
the statement return <exp>; where <exp> should be of the correct
type to be returned. Various examples of different ways a function can
return are below:
#include <iostream>
using namespace std;
/*
We tell the compiler the function header,
but we don't actually provide implementation
*/
int add(int, int);
int main(){
int x = 1;
int y = 2;
cout << add(x,y) << endl;
return 0;
}
/*
The definition of add() The header here must
match the declaration
*/
int add(int a, int b){
return a + b;
}#include <iostream>
using namespace std;
//we run into the closing bracket and exit
void f(){
cout << "Hello, world!" << endl;
} //returns here
//early return from void function
void g(double x, double y){
if (y == 0){
cout << "y can't be 0" << endl;
return; //returns here
}
cout << "Calculating..." << endl;
double z = (x * x + y * y)/y;
cout << "The answer is " << z << endl;
}
//return from non-void
string h(string firstName, string surname){
if (firstName == "" || surname == ""){
return "Default Name"; //returns here
}
return firstName + " " + surname; //returns here
}
int main(){
return 0;
}11.1.4 Invoking Functions
In order to actually use a function, we need to invoke or call it. When a function is invoked, control is passed to the function which performs the defined task. When the function terminates, control returns back to the line where we first invoked the function. To invoke a function, we simply need to pass the required parameters (of the correct type) along with the function name. Additionally, if the function returns a value, we can store it in a variable. The following example illustrates this for a function that calculates the minimum of two numbers.
#include <iostream>
using namespace std;
int min(int a, int b){
if (a < b){
return a;
}
//why don't I need an else here?
return b;
}
int main(){
int x, y;
cin >> x >> y;
int m = min(x,y);
cout << "The min of " << x << " and " << y <<" is " << m << endl;
m = min(x,2); //we can pass literals or variables
cout << "The min of " << x << " and 2 is " << m << endl;
return 0;
}
11.2 Pass-by-value and references
When invoking a function and sending variables as input to the function, C++ provides two ways of doing so: pass-by-value and pass-by-reference. In this section, we will discuss the difference between these two approaches, and when to prefer one over the other.
11.2.1 Pass-by-value
By default, variables are passed into a function by value. This means that it is not the variable itself being sent into the function, but rather a copy of its value. To see what this means, let’s look at a small example:
#include <iostream>
using namespace std;
int increment(int x){
x = x + 1;
return x;
}
int main(){
int x = 0;
cout << increment(x) << endl; //prints 1
cout << x << endl; //prints 0; function didn't change x
int y = 7;
cout << increment(y) << endl; //prints 8
cout << y << endl; //prints 7; function didn't change y
return 0;
}In this example, we have a function called increment that takes in
parameter x, adds 1, and then returns the answer. In our main
function, we call this increment function and pass in a variable x.
Note that even though the variables have the same name, because it is
being passed by value, it is not the variable x, but rather its
value \(0\) which is being sent to the function. Thus when we print x on
Line 11, its value has not changed. The same applies to y. In general,
this means that the function cannot alter the arguments passed into the
function.
11.2.2 Pass-by-reference
Because it is the value of the variables that is passed to a function, the original variables are unaffected by any operations that happen within that function. But what if we don’t want that to happen? What if we actually want to modify the original variables?3 Fortunately C++ provides a mechanism for doing so—instead of passing variables to functions by value, we can instead do this by reference. To understand how this works, we must first understand the concept of variable addresses.
A variable address specifies the location of a variable in memory. The
address operator & can be used to obtain the address of any variable
(which is displayed as a hexadecimal number). For example:
double x;
cout << &x << endl; //prints the location of xIn the following program, we declare a number of variables and investigate their addresses:
#include <iostream>
using namespace std;
int main(){
int x = 2; // Declare and initialize an int
float y = 5.0f; // Declare and initialize a float
double z = 7.0; // Declare and initialize a double
cout << "x’s value: " << x << " x’s address: " << &x << "\n";
cout << "y’s value: " << y << " y’s address: " << &y << "\n";
cout << "z’s value: " << z << " z’s address: " << &z << "\n";
cout << "size of x: " << sizeof(x) << " bytes" << "\n";
cout << "size of y: " << sizeof(y) << " bytes" << "\n";
cout << "size of z: " << sizeof(z) << " bytes" << "\n";
return 0;
}
/*
x’s value: 2 x’s address: 0x7fffda1837d0
y’s value: 5 y’s address: 0x7fffda1837d4
z’s value: 7 z’s address: 0x7fffda1837d8
size of x: 4 bytes
size of y: 4 bytes
size of z: 8 bytes
*/In the above, we use the sizeof operator to determine how many bytes
of memory each variable takes up. The most important thing to note about
the above is the offsets (that is, the differences) between the memory
locations of the three variables. The memory location of z is 4 more
than that of y, which itself is 4 more than that of x. Given that
both x and y are exactly 4 bytes large, this implies that all the
variables are stored next to each other in memory!
Now let us look at a more complex example by introducing a function:
#include <iostream>
using namespace std;
int square(int x) {
cout << "In function square(), x is located at " << &x << endl;
return (x * x);
}
int main() {
int x = 2;
int squared;
cout << "In main():\n"
<< " x is located at " << &x << endl
<< " squared is located at " << &squared << endl
<< "Before square() function call:\n"
<< " x = " << x << endl
<< " squared = " << squared << endl;
squared = square(x);
cout << "After square() function call:\n"
<< " x = " << x << endl
<< " squared = " << squared << endl;
return (0);
}
/*
In main():
x is located at 0x7fffe865e6f4
squared is located at 0x7fffe865e6f8
Before square() function call:
x = 2
squared = 0
In function square(), x is located at 0x7fffe865e6dc
After square() function call:
x = 2
squared = 4
*/The most important thing to notice here is that we invoke square with
argument x, which is at location 0x7fffe865e6f4. However, the
parameter x belonging to the function square is at a different
location! Thus the two variables do not refer to the same space in
memory, and so modifying one does not modify the other—the x of
square is different to the x of main.
If we want in fact would like for the two variable to be the same (that is, refer to the same memory location), we can achieve this using pass-by-reference as opposed to by value. In the following example, the first parameter is passed by value, while the second is passed by reference:
void func(int param1, int ¶m2){
// note the & symbol in front of param2
}Let’s now look at how this works in practice. Imagine we have a function that computes both the square and cube of a number. We cannot return both values, since we can return at most one object. However, we can get around this restriction using pass-by-reference as so:
#include <iostream>
using namespace std;
void squareCube(int x, int &y, int &z) {
cout << "In function squareCube():\n"
<< " x is located at " << &x << "\n"
<< " y is located at " << &y << "\n"
<< " z is located at " << &z << "\n";
y = x * x;
z = x * x * x;
}
int main() {
int x = 2, squared, cubed;
cout << "In main():\n"
<< " x is located at " << &x << endl
<< " squared is located at " << &squared << endl
<< " cubed is located at " << &cubed << endl
<< "Before squareCube() function calls:\n"
<< " x = " << x << endl
<< " squared = " << squared << endl
<< " cubed = " << cubed << endl;
squareCube(x, squared, cubed);
cout << "After squareCube() function call:\n"
<< " x = " << x << endl
<< " squared = " << squared << endl
<< " cubed = " << cubed << endl;
return 0;
}In this example, we have specified that y and z are passed by
reference to the function. Thus the original variables are in fact
changed by the function. When we compute the answers and store them in
y and z, we are therefore also storing them in squared and cubed
(see Line 25).
If we investigate the output of the program, we find that squared and
y share the same memory location, as do cubed and z. This is
because they were passed by reference, and because they share the same
memory location, any change to y affects squared, and the same for
the others!
In main():
x is located at 0x7fffc3f9cc44
squared is located at 0x7fffc3f9cc48
cubed is located at 0x7fffc3f9cc4c
Before squareCube() function calls:
x = 2
squared = 0
cubed = 0
In function squareCube():
x is located at 0x7fffc3f9cc2c
y is located at 0x7fffc3f9cc48
z is located at 0x7fffc3f9cc4c
After squareCube() function call:
x = 2
squared = 4
cubed = 8As a final note, the idea of a reference is a general concept, and
does not only apply to passing variables to functions. We can think of a
reference as an alternative name for an object. In the example below, we
create a reference to a variable i.
int i = 0;
int &r = i;
r = 9; //i becomes 9 also!Any time r changes, so does i (and vice versa).
11.3 Scope
A related concept to memory addresses is that of scope, which refers to the visibility, accessibility and lifetime of objects and functions. In other words, the scope of a variable or function determines when it is valid to use that variable. The scope of a variable or function is ultimately determined by where that variable or function was declared.
11.3.1 File scope
A variable or function is said to have file scope if it is declared outside of a function definition. Variables declared outside a function are often called global variables. By definition, all functions have file scope, since they are not declared inside another function. If a program consists of multiple files, then each file has no knowledge of any variables declared outside itself.
If a variable or function has file scope, it can be referenced or used anywhere in the file after where it was first declared. In the image below, we have three functions and two global variables. Their scopes (that is, when they can be used) are indicated by coloured arrows.
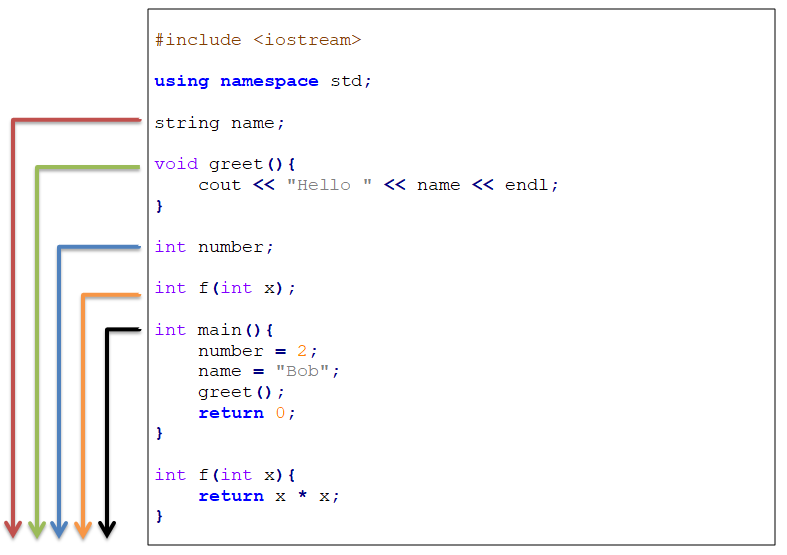
Figure 11.1: The coloured arrows indicate the scope or lifetime of the various functions and variables. They can be used anywhere below the line they were first declared.
11.3.2 Block scope
In C++, a block is any segment of code within curly braces. If a variable is declared inside a block, then it only exists within that block. As soon as the closing brace is reached, the variable ceases to exist. Such variables are known as local variables.
In the diagram below, the colour arrows and lines indicated the scope and lifetime of local variables that have been declared within blocks. Notice that each variable only exists and can be referenced within the block. As soon as the closing brace is reached, that variable is lost. Note too that function parameters are local variables, and exist only until the end of the function
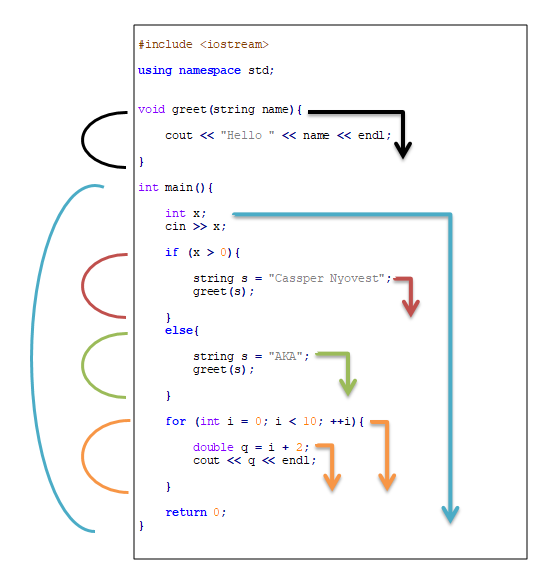
Figure 11.2: The coloured arrows indicate the scope or lifetime of the local variables. The rounded lines on the left indicate blocks of opening and closing braces.
11.3.3 Nested scope
As we have seen with nested loops and if-statements, we can have nested blocks. Variables defined outside a nested block carry into the block. If a variable inside an inner block has the same name as one in an outer block, the outer variable will be hidden, and only the inner variable can be referenced.

Figure 11.3: The coloured arrows indicate the scope or lifetime of the local variables. Note that when outerScope is printed inside the inner loop, its value is 5 and not 10, because it has hidden the outer variable with the same name. Also note that we can create our own blocks if we wish, simply by using opening and closing curly braces (as we have done for p).
The reason it is forbidden is that C++ was initially designed to be backward compatible with its predecessor programming languages B and C. Since these languages do not allow for one array to be assigned to another, neither does C++.↩︎
This is a very good reason for using pointers. For example, imagine you wrote a function that searches an array and returns a pointer to the element in the array with a particular value. What if there is no such element matching that value? What should we return in that case? A pointer that points to “null” is a good candidate in this case.↩︎